When deploying local models or when accessing remote API based LLMs with one's tools of choice, there comes a time (and that time is now), when the options presented are vast and various. One may consider, just give me "the default", but there is no default model. These days we have variants, where one LLM has been quantized or re-trained or post-trained or adapted in various ways to fine tune its abilities and focus.
Let's inspect one of my favorites lately, Qwen3-235B. This is not a model that one commonly sees running outside of large compute clusters and supercomputers, because the 235 billion parameters require substantially more resources than most infrastructures have available. Often when we see Qwen3 in-use on not-supercomputers, it's the 32B variant, which can run well enough on a 16GB+ vRAM capable GPU. Querying the models on Huggingface and one will see there are 32B on the low-side all the way to 480B for the supercomputers and research clusters, and many customized ones built from the originals.
Parameter quantity aside, as we're not focused on that at the moment, let's look at the primary high-level differences, as well as low-level technical differences, between LLM variants like "Coder", "Thinking", "Instruct". Over at the Cerebras Inference Cloud we can use the following types.
| Qwen3-32B | Qwen3-235B-Coder | Qwen3-235B-Instruct | Qwen3-235B-Thinking |
|---|---|---|---|
| Base LLM | Code Generation | Sequence Executions | Complex Reasoning |
High Level Differences
- Base Model: Generalist, no task specialization.
- Coder: Focuses on programming efficiency (e.g., auto-completion, error fixing).
- Instruct: Prioritizes user safety and conversational alignment (e.g., chatbots).
- Thinking: Targets structured reasoning (e.g., math proofs, logical puzzles).
| Variant | Purpose | Users | Features |
|---|---|---|---|
| Base | General-purpose language modeling |
Researchers, Developers |
Broad knowledge coverage, foundational capabilities for text generation |
| Coder | Code generation & understanding |
Software Developers |
Optimized for programming tasks (code completion, debugging, multi-language support) |
| Instruct | Instruction-following for conversational tasks |
End-users, Chatbots |
Aligned with human preferences, safety filters, chat template adherence |
| Thinking | Complex reasoning & step-by-step problem-solving |
Analysts, Researchers |
Enhanced logical reasoning, chain-of- thought generation, multi-step inference |
Low Level Differences
- Tokenizer: Coder extends vocabulary for code symbols (e.g.,
def,->), while others reuse the base tokenizer. - Fine-Tuning: Instruct uses RLHF for alignment; Thinking uses process-based rewards for intermediate steps.
- Decoding: Thinking enforces iterative step generation via modified KV-cache management, unlike autoregressive defaults.
- Loss Functions: Coder weights syntax validity; Thinking penalizes incorrect reasoning paths early.
| Variant | Data | Arch | Loss | Infer |
|---|---|---|---|---|
| Base | General web text, CommonCrawl, books, articles, balanced domain coverage |
Standard Transformer architecture, no task-specific changes |
Standard cross- entropy loss over next-token prediction |
Autoregressive generation; neutral tone, no task- specific formatting |
| Coder | Code repositories, 30%+ code data |
Extended tokenizer with code-specific tokens; syntax-aware positional embeddings |
Weighted cross- entropy loss favoring syntactically valid code constructs |
Generates code with proper indentation, supports infilling |
| Instruct | Instruction-response pairs (self-instructed data, human- annotated dialogues) |
No structural changes; fine-tuned attention layers for instruction parsing |
SFT + RLHF, Proximal Policy Optimization with safety rewards |
Outputs structured responses |
| Thinking | Reasoning datasets (GSM8K, MATH, HotpotQA), iterative problem-solving examples |
Added "reasoning head" for intermediate step prediction; modified KV-cache for iterative decoding |
Process-based supervision loss (rewarding correct intermediate steps) |
Explicitly outputs reasoning steps (eg, "Step 1: ... Step 2: ...") before final answer |
Use Case Mapping
- Need code generation? → Coder
- Building a chatbot? → Instruct
- Solving multi-step problems? → Thinking
- Researching foundational capabilities? → Base
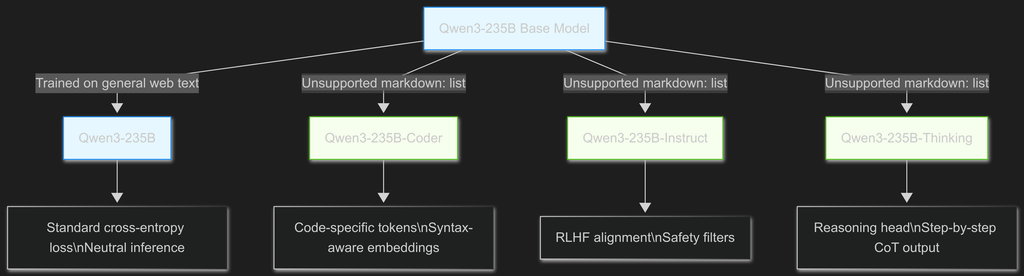
Visualizing Decisions via Flowchart
Visualizes the evolution from base model to specialized variants, emphasizing technical divergence points, which you can see in the live rendering panel over at Mermaid.Live
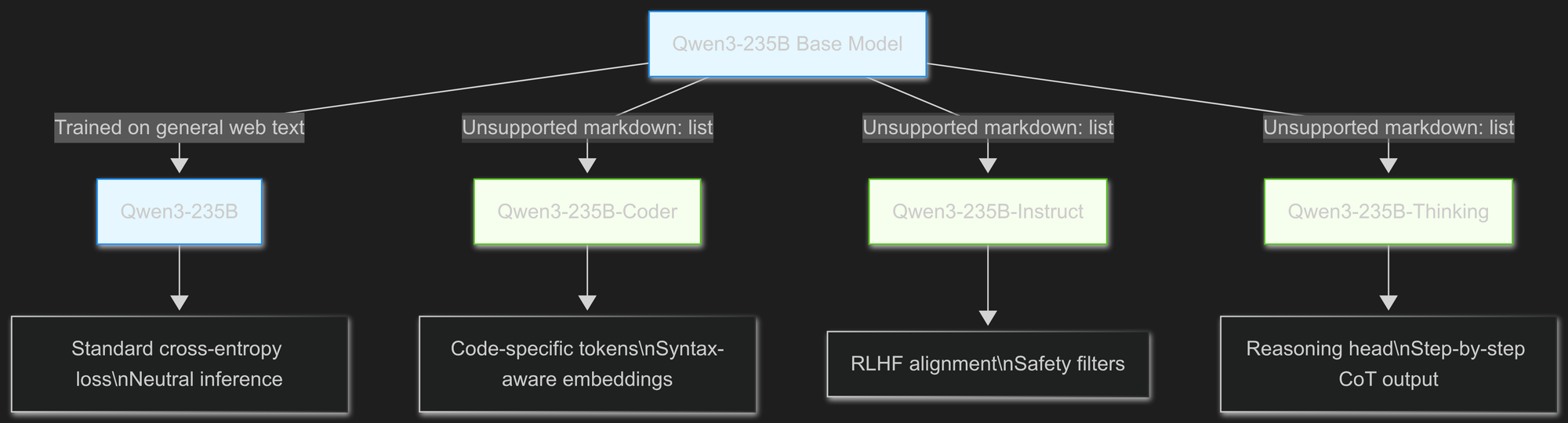
graph TD
A[Qwen3-235B Base Model] -->|Trained on general web text| B[Qwen3-235B]
A -->|+ Code corpus & tokenizer extension| C[Qwen3-235B-Coder]
A -->|+ SFT/RLHF on instructions| D[Qwen3-235B-Instruct]
A -->|+ Reasoning datasets & iterative decoding| E[Qwen3-235B-Thinking]
B --> B1["Standard cross-entropy loss\nNeutral inference"]
C --> C1["Code-specific tokens\nSyntax-aware embeddings"]
D --> D1["RLHF alignment\nSafety filters"]
E --> E1["Reasoning head\nStep-by-step CoT output"]
classDef base fill:#e6f7ff,stroke:#1890ff;
classDef variant fill:#f6ffed,stroke:#52c41a;
class A,B base;
class C,D,E variant;


