
Less prose this morning, more focus on home-lab and new OSS tech.
What is LoRA and why is it not LoRaWAN?
It's an acronym for "Low Rank Adaptation", which is an optimization method for LLMs that can dramatically reduce resource requirements while optimizing for post-training re-trains.
- Neural Nets: LoRA: Low-Rank Adaptation of Large Language Models
- WAN Nets: LoRaWAN is a Low Power, Wide Area (LPWA)
What is Auto-Round and why should we care?
Another neural-network optimization tool, specifically for quantizing large language models into "still large but optimized for specific precision". Intel released a Q4KS quantized version of the GPT-OSS-20B model on Huggingface for those who want a high-performance model on lower resource hardware.
- This algorithm helps engineers run models originally intended for Very Large Systems With Lots of VRAM to run on lower-spec systems which are often optimized on
Tokens/sec per Watt (Tk/s/W). - Additionally, it allows models which are expected to run on Nvidia GPUs to run on alternate hardware (CPU, HPU, etc), multiple calibration datasets, mixed-bit Quantizing, etc.
- Reference: Intel Auto-Round Quantizer
64GB vRAM GPUs vs Cerebras Cloud
The new big news this week has been OpenAi's release of two OSS models, GPT-OSS-20B and GPT-OSS-120B, which are quite exciting for technical reasons which I won't go into right now.
So, a quick comparison with running GPT-OSS-20B on a local-at-home GPU host vs the inference cloud at work - where we're running the GPT-OSS-120B variant of the model (feel free to try that here: https://cloud.cerebras.ai)
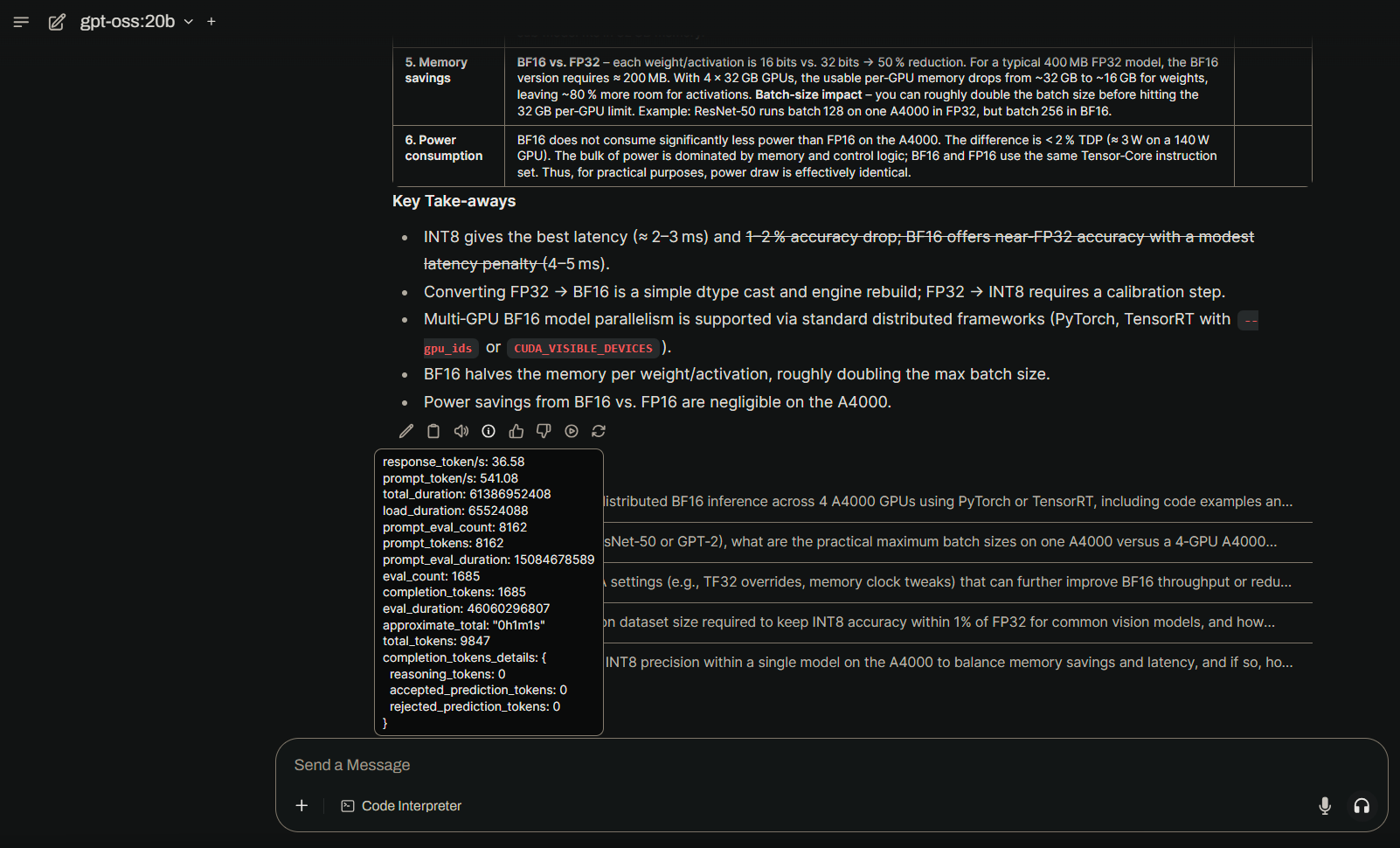
First, a screenshot of the local system running Open-WebUI with Ollama backend. See the hover-box for the tokens/sec performance values.
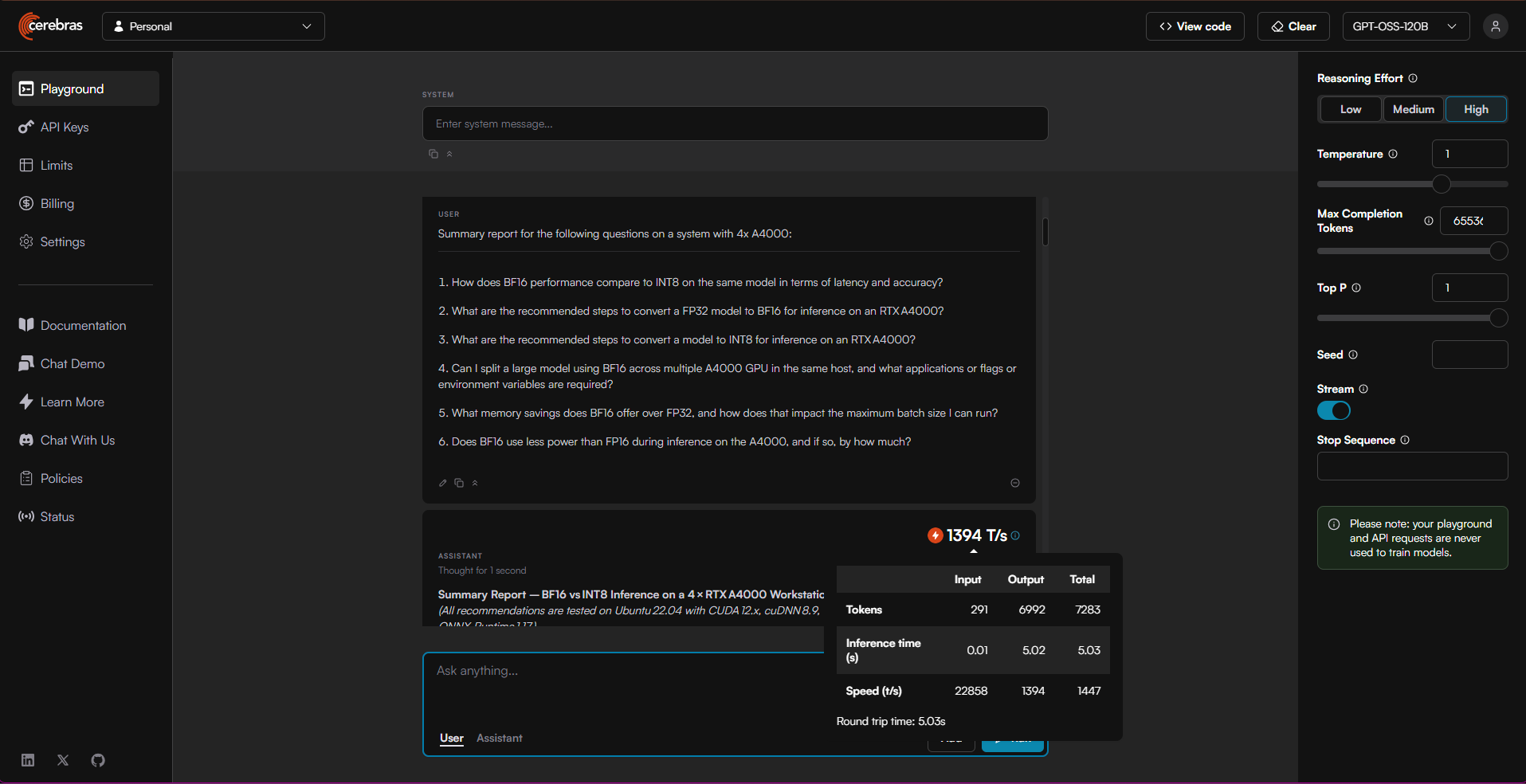
And then we see the tokens per second for the Cerebras cluster, running GPT-OSS-120B variant of the model, which is executing on millions of cores for the cluster and multi-TB of vRAM (equivalent terms).
| Cerebras UI Term | Corresponds to | Explanation |
|---|---|---|
| Input tokens/s | Prompt tokens/s | Speed of processing the input/context tokens (prefill phase) |
| Output tokens/s | Response tokens/s | Speed of generating new tokens sequentially (generation phase) |
| Total tokens/s | Combined metric | (Input + Output tokens) / total processing time |
Using the same prompt query we have token rates for the local development system:
| Prompt Token/sec | Response Token/sec | System | Cores |
|---|---|---|---|
| 541/s | 36/s | 4x A4000 | 44,352 |
| 22,858/s | 1,394/s | multi-CS-3 | millions |
Big numbers! 😃


